Building a network stack for our browser extension

This probably sounds a bit crazy. Or, you may have forgotten what a network stack is.
But before you dismiss the concept of a layered protocol stack inside of a browser extension as ravings by a madman, or a concept too convoluted to bother understanding, let me provide some context.
We’ll go over the background info of:
- What our browser extension does
- What the architecture of a MV2 browser extension looks like
- How the components of a browser extension communicate
- Our communication system’s breaking point (the problem)
And then we’ll break down what a network stack is, and why it made sense as the solution to our problem.
So, what does Jam do, anyway?
At Jam, our engineering team builds a browser extension for reporting bugs.
Our extension automatically captures bug data, such as:
- console logs
- network requests
- screenshot/video/DOM instant replay
- page metadata
- repro steps
- device info, timestamp, viewport size, etc.,
So that when a Product Manager, QA specialist, Designer, etc., files a bug, the bug automatically contains all the info an engineering team needs to debug the bug.
Engineers like this because they don’t need to hop on call. Bug reporters (PMs, QAs) like Jam because it integrates with issue trackers (like Jira and Linear) so they can rapidly fire off a bug report with all the data embedded inside it.
That’s the gist. Underneath the surface, there are a lot of moving pieces that make this possible.
What do the components of a browser extension look like?
Note: at time of writing, we’re using the Manifest v2 (MV2) architecture, supported by Firefox and Chrome/Chromium-based browser extensions.
Within a browser extension, there are a handful of different pieces (all of which are optional):
- One background script, which is persistent in the background
- One popup window per browser window
- One or more content scripts per browser tab
- One or more host scripts per browser tab
Note: This is a simplified model. For example, if your extension is running in split mode (which is a non-default behavior), you can have multiple background script instances. But generally, this structure applies for nearly all browser extensions.
Take for example a Chrome instance with two windows open, with each window having two tabs open. A browser extension running on this Chrome instance could be arranged like so:
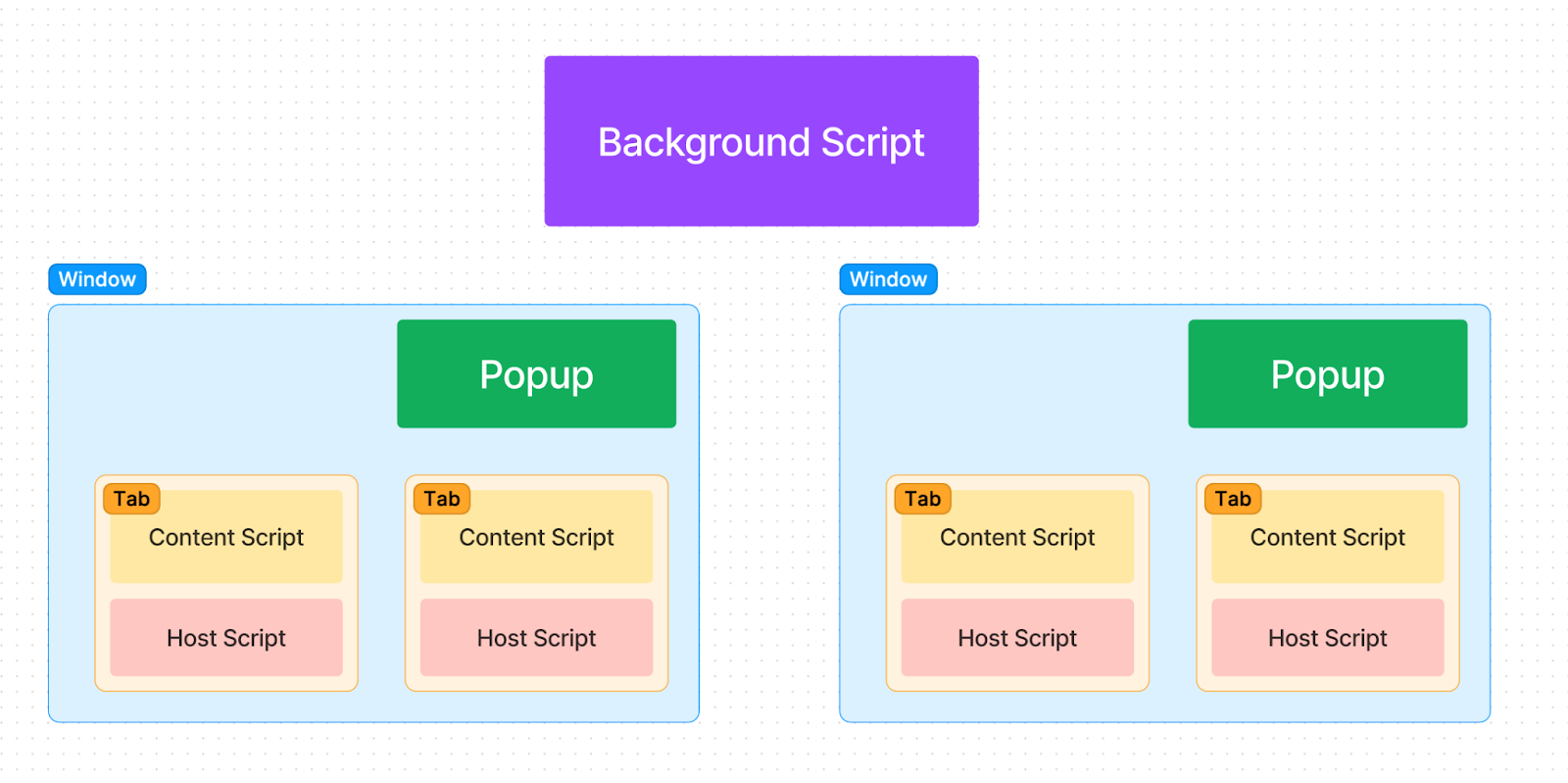
How can the components of a browser extension communicate?
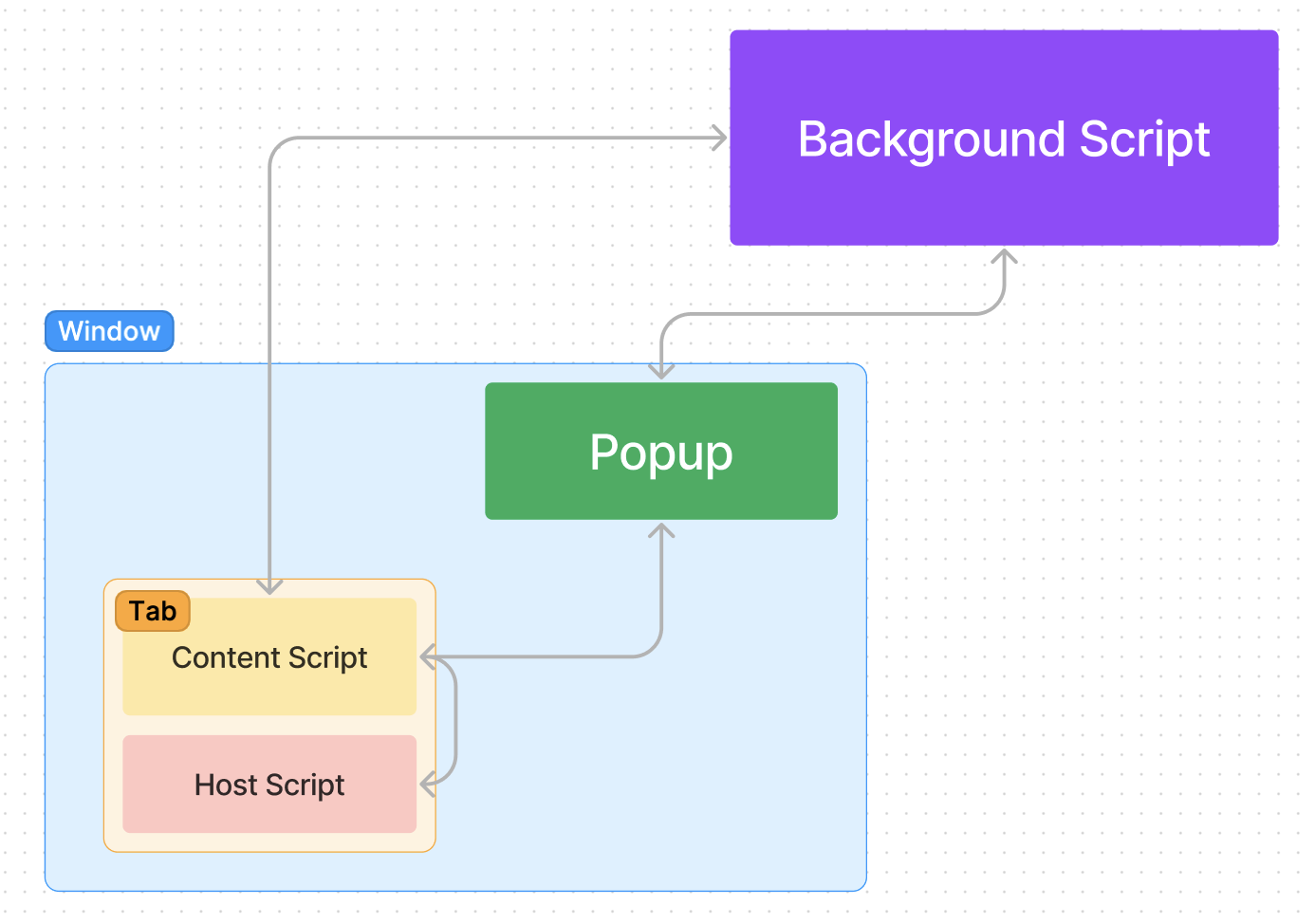
Across the different components of the browser extension, there are a few different messaging APIs. Each API is used to communicate between different components.
These APIs bridge the following components:
- We can use chrome.runtime.sendMessage between:
- popup and background (bidirectional)
- content script to popup (one way)
- We can use chrome.tabs.sendMessage between:
- background to content script (one way)
- popup to content script (one way)
- We can use window.postMessage between:
- content script and host script (bidirectional)
In essence, all of the components are connected, like so:
But of course, if sending messages was as easy as this diagram seems, this blog post wouldn’t exist.
What messaging difficulties does this setup have?
For a long time, we used the native APIs directly.
However, with native APIs alone, we have the following issues:
- Different underlying messaging APIs: Each component has its unique way of sending messages.
- Messages have size constraints (on some APIs): Some messages are too big to fit through the API pipeline.
- Some components cannot communicate directly: Certain components can't talk directly, requiring a 'middleman'.
- Multiple Tabs, Popups can exist independently: Keeping track of multiple, independent components can be tricky.
- Messages can be dropped: e.g. Popup is closed, Tab gets closed while receiving, Tab’s thread is processing so much that the event loop can’t pull queued messages + respond/ack them before they time out.
- Sharing object URLs not allowed to/from an incognito context: sending object URLs (a trick for circumventing message size constraints) from your background script to a content script won’t work, if the content script is in an incognito tab.
This last point was what finally forced us to build a network stack.
Hitting our breaking point: Incognito
So, let me provide the business context behind this feature.
Some of Jam’s biggest power-users do Quality Assurance (QA). They aim to test and break an app as fast as possible, going through dozens of flows over the course of a day, doing manual regression tests, and putting new features under a stress test before release.
When you’re testing so many flows, Incognito Mode is an essential part of your toolkit. It lets you instantly access a logged-out instance of your web app, which makes testing new user flows much easier. Plus, some apps have different behavior in incognito mode, which requires additional testing (looking at you Netflix, why won’t you let me use incognito mode).
All that to say, adding incognito support to Jam was important.
Why did we need to rebuild?
In order to understand our problem with our system up until now, we need to understand the flow for a user creating a bug report in incognito.
Before a user can submit a bug report, we need to display a preview of the bug report in the tab they’re filing the bug from.
This preview shows the user their network errors, lets them trim videos/instant replays, annotate screenshots, write a title/description, and directly file bug reports to an issue tracker or Slack channel, if they wish:

To create this preview, data is sent from the background script to the content script. Some elements of preview data (e.g. DOM Instant Replay) can’t fit in a single message: they exceed the size constraint of the chrome.tabs.sendMessage API.
To get around this on non-incognito tabs, we use a neat trick: you can create a URL for a JavaScript object using window.URL.createObjectURL on one end, and fetch the URL on the other end to transfer large objects. Using this method, both processes can share large objects that wouldn’t fit in a single message.
Except this method won’t work between the background script and an incognito tab. Incognito tabs have different object URL contexts. Without this trick, we can’t circumvent message size constraints. Message chunking must be implemented.
But our existing system is a simple layer directly above native messaging APIs, so adding chunking requires a rebuild.
Do our problems seem familiar?
Remember our messaging difficulties from before? Those problems are actually …general networking problems.
- Different underlying messaging APIs? ← Different link layer protocols (Ethernet vs Wifi)
- Messages have size constraints (on some APIs)? ← Wifi/Ethernet packet-size limit
- Some components cannot communicate directly? ← Routing can require hops
- Multiple Tabs, Popups can exist independently? ← Multiple independent devices
- Messages can be dropped? ← Packet loss
- Sharing object URLs not allowed to/from an incognito context? ← Separate machines, data must be serialized
Looks like our browser extension’s components have similar communication problems to devices accessing the Internet. The solution to our shared problem set? Create a network stack.
What is a network stack?
A network stack is a set of layered protocols for communication. Each protocol solves a specific problem. Each protocol layer builds on guarantees offered by previous layers.
Take the TCP/IP stack, for example. This stack is used by Internet applications, such as websites or video games:
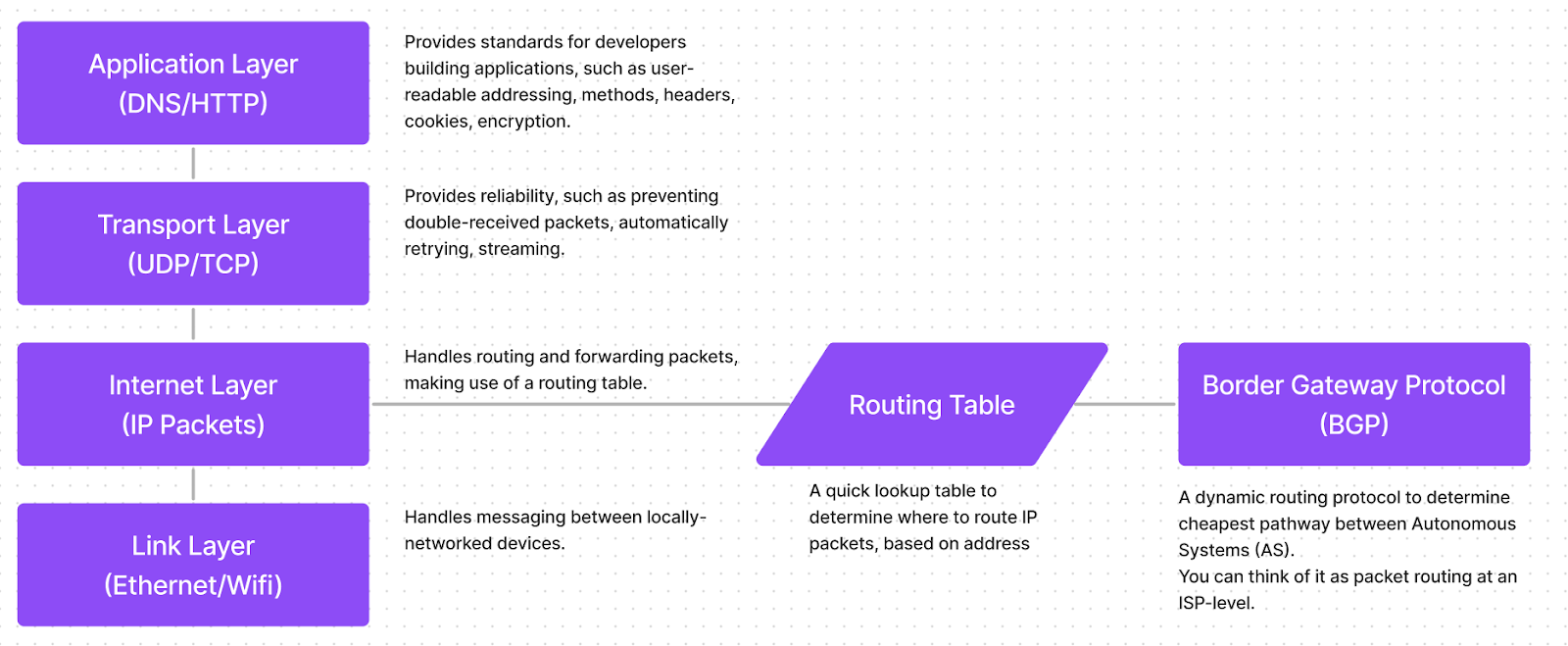
At the bottom, we have the link layer, connecting physical devices.
Next, the Internet layer builds on top of the link layer, allowing routing and forwarding across devices, so messages can be sent between devices that aren’t physically connected.
The internet layer makes use of a routing table. This table is used to determine where packets should be sent, based on their IP address. Since each machine isn’t directly connected to every other machine on the internet, a per-machine routing table keeps track of which addresses should be used for packet forwarding.
This routing table can be populated by a few sources. At the highest level, routing can be determined by a protocol called BGP (Border Gateway Protocol), the communication protocol between Internet Service Providers (ISPs), such as Xfinity and Verizon. From there, your ISP can populate the routing table for your router, which can populate the routing table for your individual machine.
Above the internet layer sits the transport layer, which can be as simple as UDP (a simple wrapper and checksum of an IP packet), but in the Internet’s case is typically TCP, which provides more reliability. TCP allows streaming, retries, and prevents double-delivery.
Finally, the application layer gives a well-featured layer for developers to build applications on. This layer gives us cookies, headers, encryption, status codes, and user-readable domain names. It’s much easier to build software on this layer than to attempt to use TCP directly.
These are the same abstractions we used for our extension’s messaging system.
Jam’s extension network stack
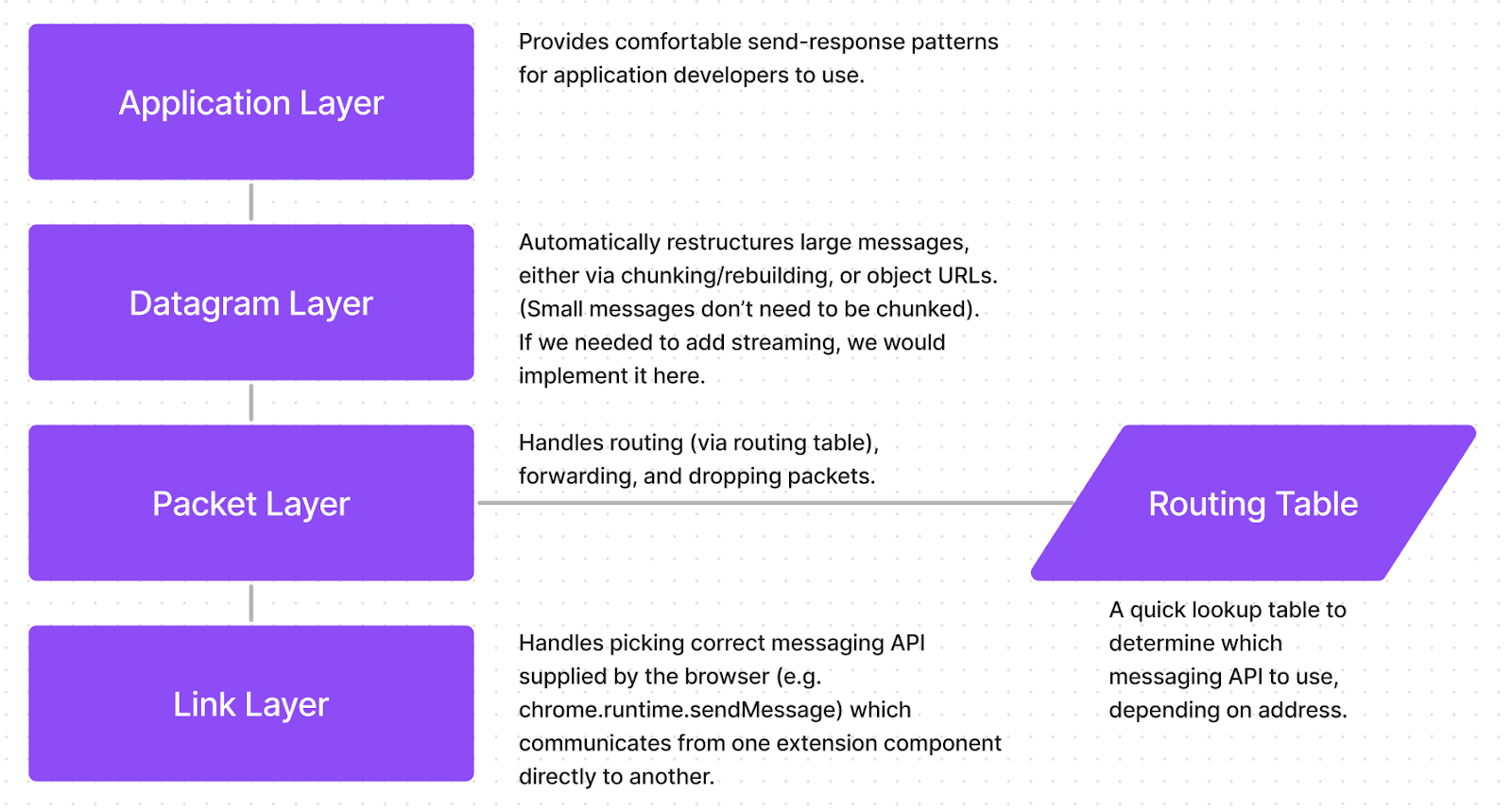
At the bottom of our extension component network stack, we have our link layer, which handles communication between directly-connected components.
Above that, our packet layer handles routing, forwarding, and dropping packets, much like the internet layer from the TCP/IP stack.
The packet layer makes use of a routing table, which is used for routing packets to the correct extension component. Since our extension components will always have the same configuration (host script is connected to content script, content script is connected to background, etc.,), we can use a static routing table, no BGP-like dynamic routing algorithm required.
Above the packet layer, we have the datagram layer. This layer was essential for implementing incognito mode support on Jam, because it allows large messages to/from incognito tabs to be automatically chunked and sent in pieces. If we need to implement message streaming in the future, we would implement it at this layer.
Finally, we have the application layer. This layer gives us a comfortable send/receive pattern that automatically creates response listeners and ties a message request back to a message response. (Imagine if HTTP requests didn’t have responses, and you’ll understand what using this stack would feel like without this layer).
Did we solve our problems?
Do you remember our earlier messaging difficulties from before? Well, here are their solutions.
- Different underlying messaging APIs? ← Abstracted by the link layer
- Messages have size constraints (on some APIs)? ← Chunking at the datagram layer
- Some components cannot communicate directly? ← Packet forwarding at packet layer
- Multiple Tabs, Popups can exist independently? ← Independent addressing at packet layer
- Messages can be dropped? ← Packet retries at datagram layer
- Sharing object URLs not allowed to/from an incognito context? ← Automatically switch to chunking if the sender/receiver is incognito (and message size is too large to fit in a single packet), at the datagram layer
So, yes! These problems feel solved. And if this system worked for the internet, it will probably scale for any other complicated communication scenarios you may imagine, where we can’t use HTTP (a second extension, a native desktop app, etc.,).
Outcomes of this project
This extension component network stack has been in production and stable for around 9 months at time of writing.
Here are a few choice benefits that our approach gave us:
Smooth rollout
Prior to this network stack we had a simpler setup, with an application layer built on top of native messaging APIs. By keeping our final application layer the same for this project, we were able to simply cutover to the new network stack, and have Incognito Mode just work.
Not only that, but as this stack was built, the rest of our team was able to continue writing code that introduced new application message types, and used more application message calls. Switching to this new system didn’t impact developer velocity.
Simpler debugging
Separation of concerns across each layer makes it easier to narrow down where an issue is happening. Tests at every layer (with simulated native message APIs) give us confidence on every layer and the system overall.
Focus on building features
Developers doing feature-work no longer need to bother with message length constraints, forwarding messages over the content-script-to-host-script-hop. Our network stack abstracts away these problems. This cuts down the amount of code we need to make a cross-component feature work, and lets our engineers focus on building product features.