Our journey with GraphQL and the trade-offs we've encountered along the way

At Jam, we initially chose GraphQL for our product due to its flexibility and ability to build lightweight and fast front-ends. However, as we’ve scaled, we have encountered challenges with GraphQL related to maintainability, debugging and monitoring.
Even within our engineering team, the jury is out on whether those tradeoffs are worth it. Some engineers prefer GraphQL because we can nest fields in one request and because we don’t need to set up many routes for all the variations of requests we make in the product. But others argue that the added obscurity in monitoring and debugging from everything in GraphQL being a POST and returning 200 is not worth it over the simplicity of REST.
We’ll shed some light on the tradeoffs between running GraphQL vs our past experiences with RESTful services. And we’d love to hear about your experiences too.
The Benefits of GraphQL
The core benefit of GraphQL is that it allows clients to request exactly the data they need, without having to set up multiple backend routes to accomplish that.
To briefly summarize how GraphQL works, the main idea is that clients have the ability to customize the exact shape of the data they are requesting.
To illustrate with a contrived example, suppose a client-side SPA wants to grab a list of all users with just two properties: name and email. The client would fire off an HTTP Post request containing a payload:
query users {
name
email
}and in response, the server would give a list of user objects containing name and email. If the client needs to add or remove properties, they simply change the shape of the requested data.
This is very similar to another query language you may be familiar with…
select id, name, email, created_at from usersSQL! Structured query language is also WYSIWYG. These query languages offer a way to describe what content you want, and it’s up to the server implementation to fetch that data. This offers a lot of flexibility for front-end applications because they can customize each query to their needs instead of using variations of similar RESTful endpoints.
One of the biggest bottlenecks in delivering a fast web-based application is the sheer amount of network requests made. You can make major improvements in latency by consolidating or caching resources. GraphQL helps in this regard because it supports batching queries into a single HTTP request! Apollo has a great blog post about batching queries here. This helps to make front-ends powered with GraphQL lightweight and fast, as they only consume the data they require, and have to wait on fewer requests to resolve.
A minor benefit is that using GraphQL makes it easier to onboard new engineers to the team. GraphQL makes it easy to introspect and explore the available data schema with tools like GraphiQL, so as a new engineer, it’s quicker to learn the API and start making contributions.
Another benefit is having a strongly typed API schema. In most RESTful applications, there’s often no strong typing contract between clients and servers. The content-type is typically application/json but that doesn’t provide any consistency guarantees that you might want.
For example, if you have some kind of REST endpoint, how do you know if an object’s property exists or is nullable or if it’s an array? Where would you enforce those semantics? On the client side, the server side, or in both places? With GraphQL, you must specify the exact typing for the requests and responses, and clients and servers must adhere to that.
However, as much as we love GraphQL for these benefits, there are some drawbacks that have become more apparent as we scale.
When it comes to debugging and monitoring, GraphQL presents a unique set of challenges compared to traditional HTTP REST APIs. Let's explore some of these issues in detail:
HTTP Status Codes and Error Handling
One major difference between GraphQL and REST APIs is how they handle errors. In a REST API, different HTTP status codes indicate the outcome of a request. For example, a 200 status code means the request was successful, while a 400 status code means there was a client error.
In contrast, GraphQL always returns a 200 status code, even if there are errors in the response body. The GraphQL spec suggests that servers respond with a structured errors field. This makes errors machine-readable but drops the semantic meaning of HTTP status codes. Everyone knows what a 404 status code means but a GraphQL server will instead return a 200 with application-specific errors in the errors field in the response. This means that to effectively debug GraphQL, you must comb through every single request to identify errors.
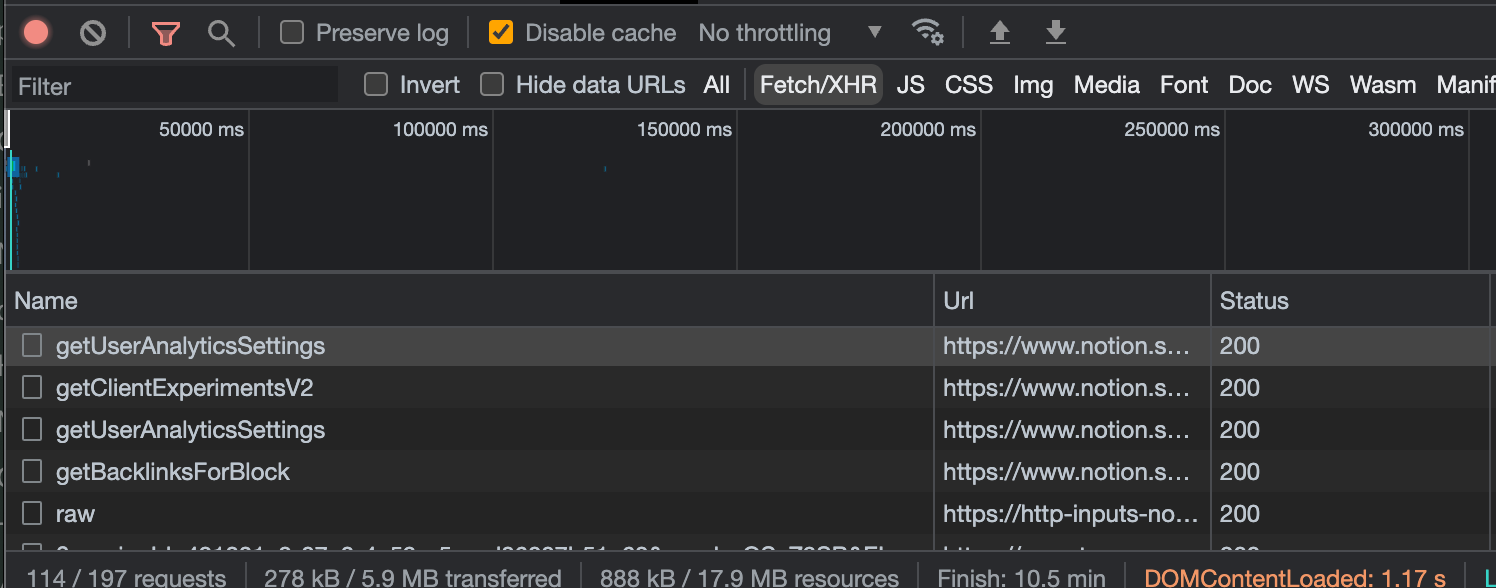
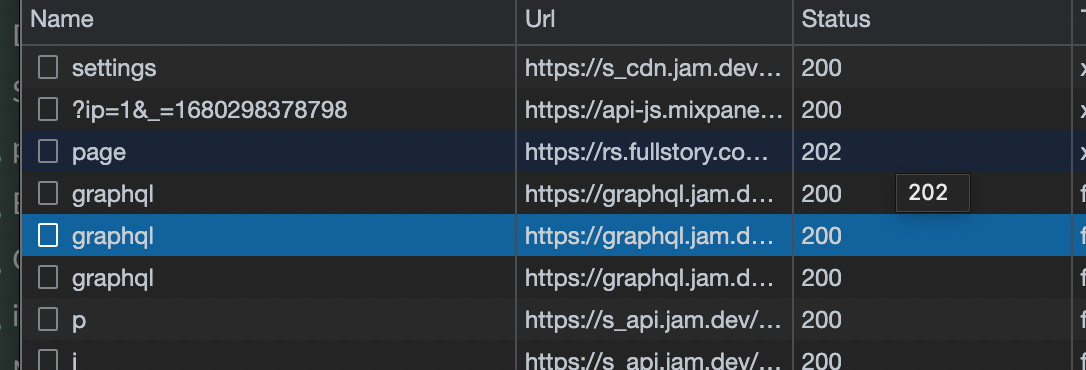
A Single Endpoint and the Lack of Per-Endpoint Metrics
In a REST API, each endpoint corresponds to a specific resource or action, making it easy to collect timing and monitoring metrics for each endpoint. These metrics provide valuable insights into the performance and health of the API.
However, GraphQL uses a single endpoint for all queries and mutations, and all queries use POST and return a 200. As a result, you don't get the same granularity of monitoring metrics that REST provides.
This creates challenges when trying to optimize performance, monitor usage, and debug issues.
To work around this, you’d have to instrument each GraphQL resolver function to capture this metadata. In our opinion, REST is much easier to work with because it is closer to HTTP in nature, and writing HTTP middleware is easy to set up for collecting status codes, URL paths and timing info for the entire request-response lifecycle.
Tooling
The tooling for setting up GraphQL can be overwhelming. We use fastify as our HTTP server which is a Node.js-based server framework. To implement GraphQL we use Mercurius and NexusJS. The client libraries are automatically code-generated using graphql-codegen. In aggregate, configuring all of these tools is not too bad but it is not a trivial task.
In our experience, GraphQL is not a simple drop-in technology. You have to buy into the ecosystem and learn about various ways of maintaining your schema file and generating client SDKs. There is an obvious maintenance burden for having to add a bunch of third-party packages whereas REST services can go really far with simple web server frameworks like express.js or fastify.
Our experience at Jam
We've had to invest significant time and resources in developing custom tooling and processes to help us monitor and debug our GraphQL implementation effectively.
Because we use Jam at Jam, we added extra logic to the dev tools section to mark GraphQL requests as errors even if they return an HTTP 200 code, if they have an errors object inside the response body.
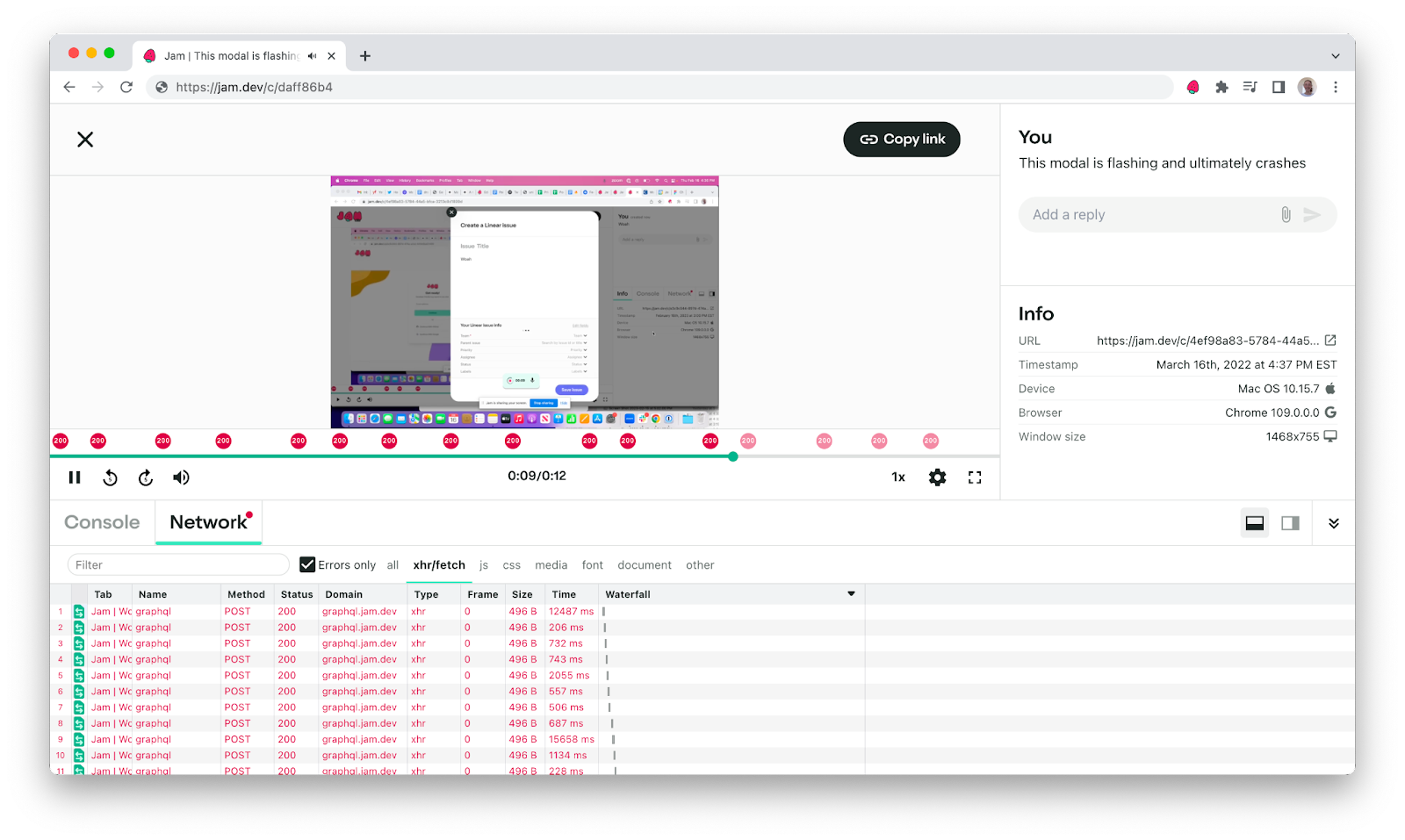
Making changes to your GraphQL schema is easy, but you have to be careful! When we first started working with GraphQL, we inadvertently caused incidents with seemingly minor changes. Simply renaming fields or deleting fields can have drastic consequences. Not all clients are using updated extensions right away so the server will return errors for breaking changes. When we publish our extension to the Chrome Web Store, the new release isn’t released to everyone immediately, so we always have to consider GraphQL compatibility with outdated clients.
I wrote another post on GraphQL strategies to help you manage interactions between evolving systems more effectively that might be helpful to engineers dealing with similar challenges.
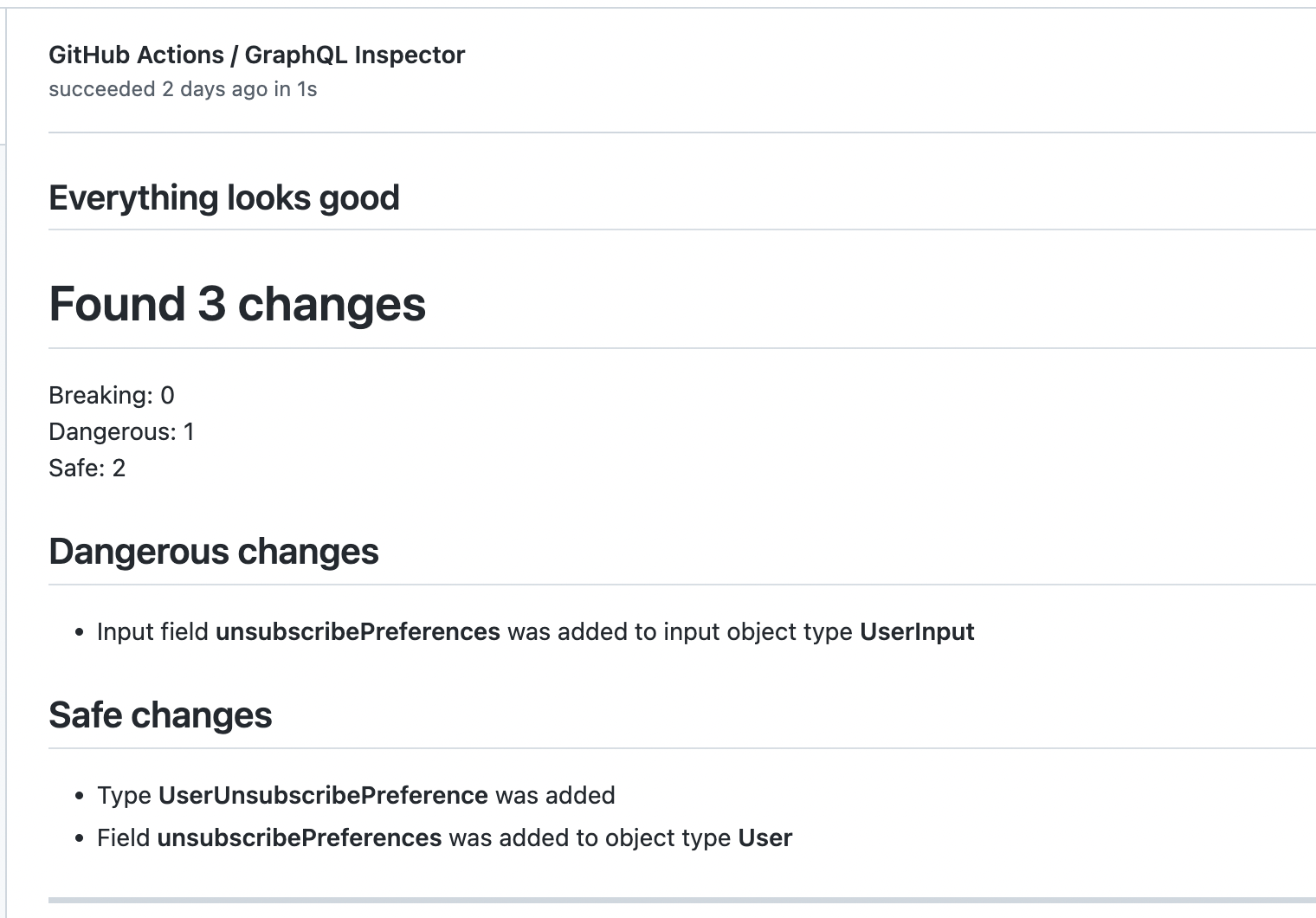
Over time, we’ve tried to remind ourselves that we need to update call sites and avoid breaking changes. In practice, this hardly worked because of how fast we needed to make changes and the sheer complexity of updating several queries. For example, marking a field optional can be non-breaking whereas making a field non-nullable is a breaking change! We needed a better system to avoid these issues or at the very least some way to mitigate some of the burdens.
To tackle this, we wanted a way to automatically detect breaking changes. This was a game-changer for us. In CI, we use GraphQL Inspector to help us detect breaking changes before committing them to production. The way it works is we configure different stages of our CI pipeline to compare GraphQL schemas to the existing schemas i.e. our staging schema is compared to the production schema. If there are breaking changes, our builds fail so we can address them. This alleviates much of the mental overhead and lets us move more quickly.
The flexibility of GraphQL might be overblown
A lot of the appeal of GraphQL is based on retrieving exactly the right amount of data needed. But in practice, this often doesn’t pan out. Sometimes we have queries that over-fetch data and other queries that under-fetch data. Sometimes we have queries that are stale and require a bit of grooming to make sure we are using all the data or are otherwise pruning unused data.
We realize that we are not perfect and that there’s still a lot of mental overhead in maintaining client queries. Just because you can fetch any data shape you want doesn’t make it any simpler. In fact, it mostly shifts complexity away from the backend and moves it to the frontend.
We think GraphQL makes a lot of sense for organizations where backend and frontend systems are siloed from each other. If a frontend engineer needs additional or reduced data, they would need to work with the backend engineer to ensure REST endpoints can satisfy their requirements. GraphQL smooths over that and makes the process easier.
But for us at Jam, engineers are full stack and often context switch so the flexibility of GraphQL isn’t all that useful since we can make whatever backend changes we need to get the job done. With GraphQL there are a lot of moving parts that need to work together in concert even for the smallest of changes. For example, when adding a field to an existing object, the SDL file must be updated, the resolver function must be added, the client GraphQL fragments must be updated, the client SDK libraries have to be regenerated, the call sites themselves must be updated, etc.
Was GraphQL the right choice for us?
Honestly, the jury is still out. But we wanted to share our experience and hear from other engineering teams’ experiences too.